一、InnoDB Buffer Pool简介
Buffer Pool是InnoDB引擎内存中的一块区域,主要用来缓存表和索引数据使用。我们知道从内存读取数据要比磁盘读取效率要高的多,这也正是buffer pool发挥的主要作用。一般配置值都比较大,在专用数据库服务器上,大小为物理内存的80%左右。
二、Buffer Pool LRU 算法
Buffer Pool 链表使用优化改良后LRU(最近最少使用)算法进行管理。
整个LRU链表可分为两个子链表,一个是New Sublist,也称为Young列表或新生代,另一个是Old Sublist ,称为Old 列表或老生代。每个子链表都有一个Head和Tail,中间部分是存储Page数据的地方。
当新的Page放入 Buffer Pool 缓存池的时候,会交其Page插入就是两个子链表的交界处,称为midpoint,同时就会有旧的Page被淘汰,整个操作过程都需要对链接进行维护。
Young 链表区存放的数据是经常访问的数据;
Old 链表区存放是即将被淘汰的数据;
一个新数据先被插入到midpoint 位置,根据LRU算法访问频率高的Page,会慢慢向Young区Head方向移动。同时访问频率低的Page会从Young区慢慢转到Old 链表的Tail,至到被淘汰。 Figure 14.2 Buffer Pool List
Figure 14.2 Buffer Pool List
算法操作流程如下:
Old区占 Buffer Pool大小的 3/8,此值可以通过 innodb_old_blocks_pct 调整,单位为百分比。
midpoint是young和Old的相交边界,新页插入的位置。
当执行一个read操作时,如select查询语句,这时InnoDB会将页读入到 buffer pool中,最初时会放在midpoint位置(放在Old区的head部分)。(这一点和传统的LRU 算法不一样,并没有放在Old的Tail位置。
如果访问的是Old区的页,会使此页被标记为”young”, 并将其向到 Young区的头部。如果由于用户操作引起的将page放在buffer pool中,当插入到midpoint位置后,立即进行访问操作,会将此page标识为”young”。而如果一个page是由于预读操作而访问的话,则不会产生立即访问这个行为,并且有可能在此page被淘汰之前一次也没有访问过。
随着数据库地运行,新page不断的插入midpoint位置,并不断地被访问到,其page慢慢向Young区的Tail位置移动,同时未被访问的page也会慢慢向Old区的Tail方向移动,最终将其从Old区的尾部被淘汰。
什么是预读?
磁盘读写,并不是按需读取,而是按页读取,一次至少读一页数据(一般是4K),如果未来要读取的数据就在页中,就能够省去后续的磁盘IO,提高效率。在InnoDB中一个page一般为14K,是操作系统的4倍,当然这个值是可以通过参数innodb_page_size调整的。
预读有哪些好处?
数据访问,通常都遵循“集中读写”的原则,使用一些数据,大概率会使用附近的数据,这就是所谓的“局部性原理”,它表明提前加载是有效的,确实能够减少磁盘IO。
三、Page 移动策略
上面我们提到过这里使用的LRU算法和传统的算法有些区别,这里我们主要介绍一下不同点。
如果使用传统算法的话,发现当我们执行一个访问频率很小的 query 时,如一个全表扫描,会把大量的数据插入到midpoint位置,短时间内多次访问的话,会导致这些数据被移动到young区(尽管这些数据以后不再访问了),并多次进行链表修改,不但大量占用了young区的空间,同时还造成了频繁修改young链表的成本,这时就需要一种方法来解决此问题。
参数:innodb_old_blocks_time
单位:毫秒
默认值:1000
此参数主要用来控制Old区的数据移动策略,如果Page在Old区停留innodb_old_blocks_time时间后,再次被访问才会向Young区移动,否则保存位置不变。这样就避免了频繁向Young区移动数据,减少维护LRU链表的成本。例如原来1秒内访问了10次,会修改Young链表10次,现在只修改一次就可以了,大大节省了LRU链表维护成本。
可以看到将此值调整大的话,将直接影响old数据向young移动的难度,从而加速old区淘汰的频繁,保护了Young区内被频繁访问的数据不被淘汰。
四、监控
在SHOW ENGINE INNODB STATUS 里面提供了Buffer Pool一些监控指标,有几个我们需要关注一下:
 内存
内存
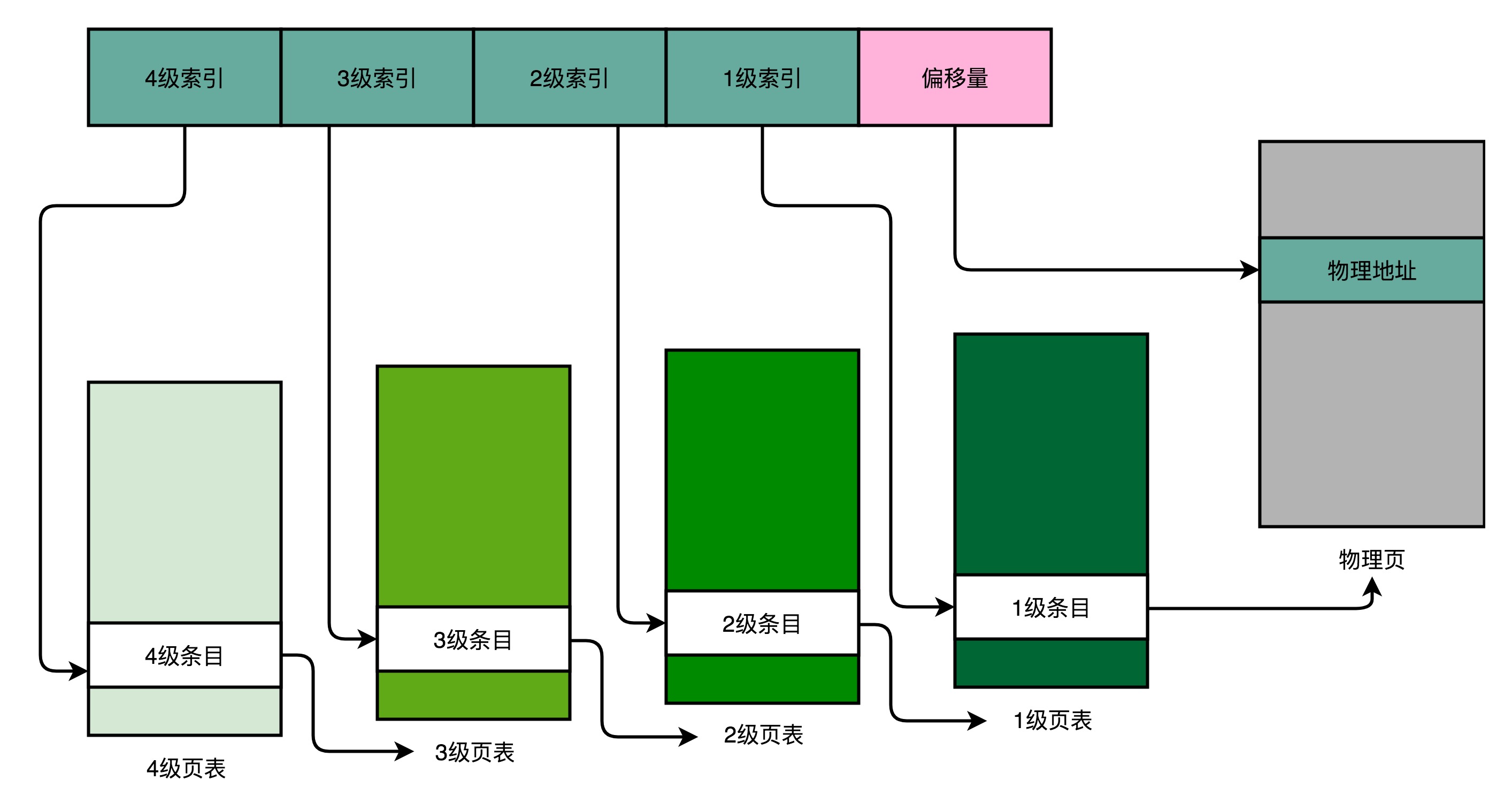
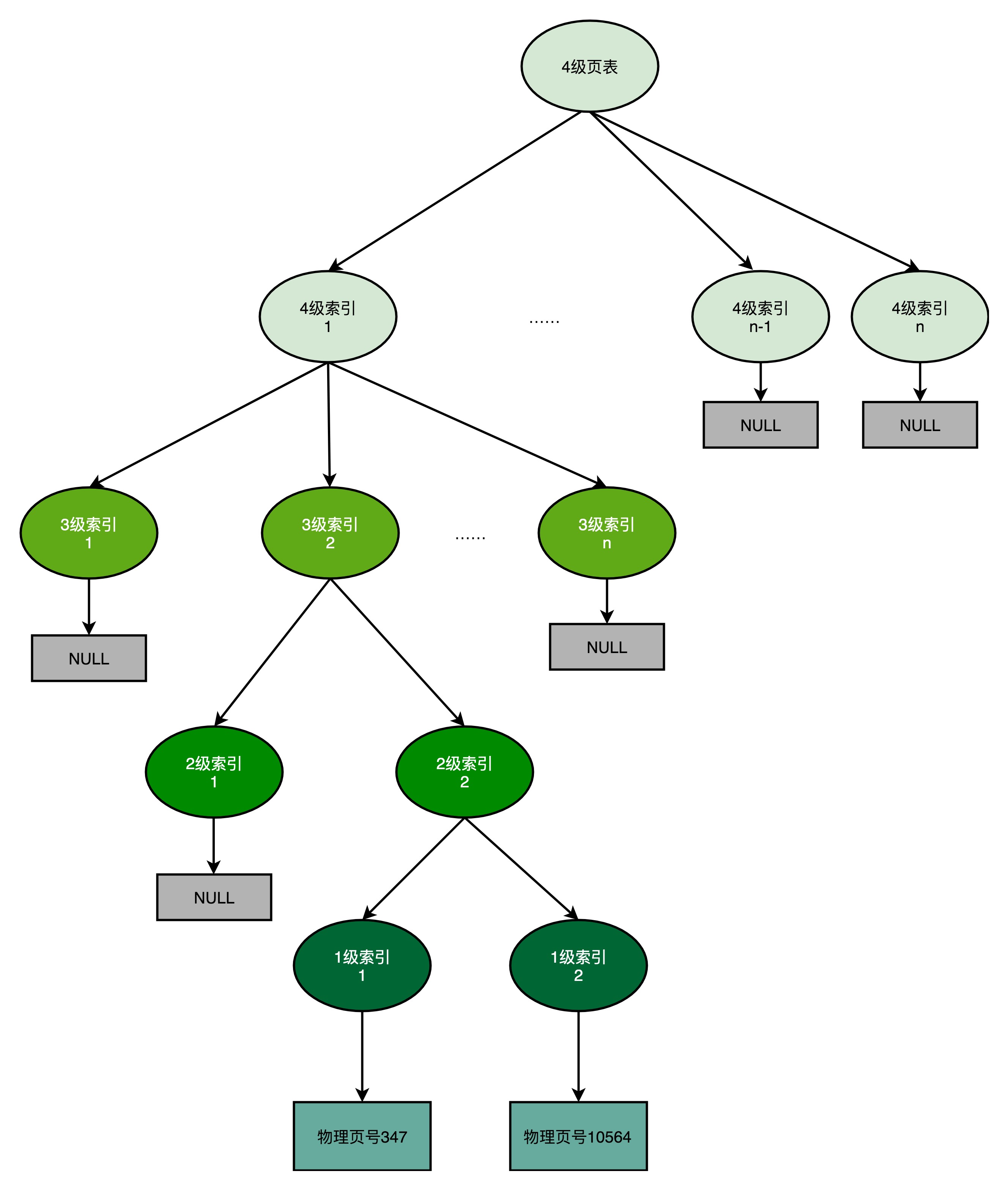 页表
页表