kubernetes 之 client-go 之 informer 工作原理源码解析
admin
- 11 minutes read - 2279 words本文主要介绍有关 client go 架构实现原理,在整个client-go架构中有一个很重要的组件就是 informer,本节我们重点对其进行一些介绍。
Informer 机制
采用 k8s HTTP API 可以查询集群中所有的资源对象并 Watch 其变化,但大量的 HTTP 调用会对 API Server 造成较大的负荷,而且网络调用可能存在较大的延迟。除此之外,开发者还需要在程序中处理资源的缓存,HTTP 链接出问题后的重连等。为了解决这些问题并简化 Controller 的开发工作,K8s 在 client go 中提供了一个 informer 客户端库,可以视其为一个组件。
在 Kubernetes 中,Informer 可以用于监视 Kubernetes API 服务器中的资源并将它们的当前状态缓存到本地(index -> store) ,这样就避免了客户端不断地向 API 服务器发送请求,直接从本地即可。
相比直接采用 HTTP Watch,使用 Kubernetes Informer 有以下优势:
- 减少 API 服务器的负载:通过在本地缓存资源信息,Informer 减少了需要向 API 服务器发出的请求数量。这可以防止由于 API 服务器过载而影响整个集群的性能。
- 提高应用程序性能:使用缓存的数据,客户端应用程序可以快速访问资源信息,而无需等待 API 服务器响应。这可以提高应用程序性能并减少延迟。
- 简化代码:Informer 提供了一种更简单、更流畅的方式来监视 Kubernetes 中的资源更改。客户端应用程序可以使用现有的 Informer 库来处理这些任务,而无需编写复杂的代码来管理与 API 服务器的连接并处理更新。
- 更高的可靠性:由于 Informer 在本地缓存数据,因此即使 API 服务器不可用或存在问题,它们也可以继续工作。这可以确保客户端应用程序即使在底层 Kubernetes 基础结构出现问题时也能保持功能。
下面一起看一下 client-go 库的实现原理
架构介绍
我们先看一下来自 官方 的 client-go 架构图
{kind=link}
整个架构图分上、下两部分,其中上部分为 client-go 的实现,而下部分是我们自己要实现的 Custom Controller,每部分由不同的组件组成,上下两部分通过虚线连接起来。其介绍请参考 https://github.com/kubernetes/sample-controller/blob/master/docs/controller-client-go.md
有时候
Controller也被叫做Operator,这两个术语的混用有时让人感到迷惑。Controller是一个通用的术语,凡是遵循 “Watch K8s 资源并根据资源变化进行调谐” 模式的控制程序都可以叫做Controller。而Operator是一种专用的Controller,用于在 Kubernetes 中管理一些复杂的 有状态 的应用程序。例如在 Kubernetes 中管理 MySQL 数据库的 MySQL Operator。
在实现 controller 时一般在 Informer 配置回调函数 Callbacks(ResourceEventHandlers)来实现 Informer 和 Custom Controller 上下两部分之间的通讯,这个在上面的链接里均有介绍。如果上图不容易理解的话,也可以参考下面两张架构图。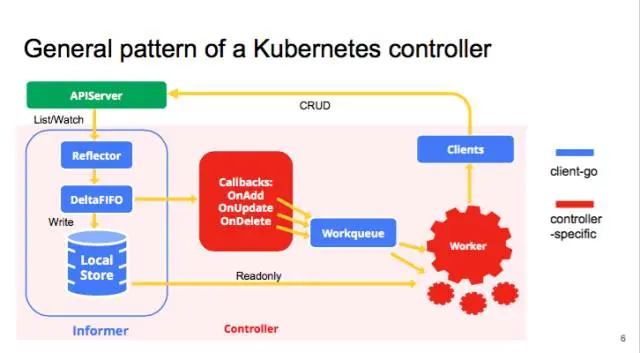

注意这里写入 workqueue 队列的是API对象的 key, 即 namespace/name;接着在控制循环 Control Loop 里先从 workqueue 读取这个 key;然后根据 key从 indexer 缓存里读取对象。如果对象不存在则说明前面是通过 DeleteFunc 写入的,则需要删除key, 否则进行其它处理,执行控制器模式里的对比“期望状态” 和 “实际状态”的逻辑了。
下面根据官网给出的架构图,我们一起看一下它的实现代码。
架构实现源码分析
这里以官方提供的 workqueue 示例为例,按照上方的架构图对其 每一个步骤 进行源码分析
入口函数为 main函数中的 go controller.Run(1, stop)
// /examples/workqueue/main.go
func main() {
...
// create the pod watcher
podListWatcher := cache.NewListWatchFromClient(clientset.CoreV1().RESTClient(), "pods", v1.NamespaceDefault, fields.Everything())
// create the workqueue
queue := workqueue.NewRateLimitingQueue(workqueue.DefaultControllerRateLimiter())
// 创建 indexer 和 informer
indexer, informer := cache.NewIndexerInformer(podListWatcher, &v1.Pod{}, 0, cache.ResourceEventHandlerFuncs{}
controller := NewController(queue, indexer, informer)
stop := make(chan struct{})
defer close(stop)
go controller.Run(1, stop)
select {}
}
func NewController(queue workqueue.RateLimitingInterface, indexer cache.Indexer, informer cache.Controller) *Controller {
return &Controller{
informer: informer,
indexer: indexer,
queue: queue,
}
}
这里创建的是一个 pods 类型的 ListWatch, 接着创建了一个带 限速率 功能的 workqueue(底层queue 的实现对应代码为 https://github.com/kubernetes/client-go/blob/v12.0.0/util/workqueue/queue.go#L64-L88), 然后调用 cache.NewIndexInformer 来创建 indexer 和 informer。
这里的 workqueue 主要是在 ResoureEventHandlers 回调时调用,对应的是第 7) Enqueue Object Key 步骤。
// /examples/workqueue/main.go
func (c *Controller) Run(threadiness int, stopCh chan struct{}) {
defer runtime.HandleCrash()
// Let the workers stop when we are done
defer c.queue.ShutDown()
klog.Info("Starting Pod controller")
// 启用 informer 服务
go c.informer.Run(stopCh)
// Wait for all involved caches to be synced, before processing items from the queue is started
if !cache.WaitForCacheSync(stopCh, c.informer.HasSynced) {
runtime.HandleError(fmt.Errorf("Timed out waiting for caches to sync"))
return
}
// 业务逻辑回调 c.runWorker
for i := 0; i < threadiness; i++ {
go wait.Until(c.runWorker, time.Second, stopCh)
}
<-stopCh
}
这里首先调用 go c.informer.Run() 来启用 informer 服务,让其在一个单独的 goroutine 运行, 其实现对应架构图中的 1~7 步骤。
接着再调用 go wait.Until(c.runWorker, time.Second, stopCh) 来实现自定义控制器的逻辑,其对应架构图中的 8~9 步骤。
下面我们先看一下 informer 服务的实现 ( https://github.com/kubernetes/client-go/blob/v12.0.0/tools/cache/controller.go#L97-L125)。
// /tools/cache/controller.go
func (c *controller) Run(stopCh <-chan struct{}) {
// 首先创建 Reflector
r := NewReflector(
c.config.ListerWatcher,
c.config.ObjectType,
c.config.Queue,
c.config.FullResyncPeriod,
)
// 启用 Reflector 服务
wg.StartWithChannel(stopCh, r.Run)
}
首先创建一个 Reflector 对象,并注入 podListWatcher 和 Delta Fifo Queue 队列, 其中 ObjectType 为 &v1.Pod{},接着启用 Reflector 服务(https://github.com/kubernetes/client-go/blob/v12.0.0/tools/cache/reflector.go#L119-L128)
// /tools/cache/reflector.go
// Run starts a watch and handles watch events. Will restart the watch if it is closed.
// Run will exit when stopCh is closed.
func (r *Reflector) Run(stopCh <-chan struct{}) {
// 启用 ListAndWatch
wait.Until(func() {
if err := r.ListAndWatch(stopCh); err != nil {
utilruntime.HandleError(err)
}
}, r.period, stopCh)
}
接着看一下 r.ListAndWatch() 实现 (https://github.com/kubernetes/client-go/blob/v12.0.0/tools/cache/reflector.go#L156-L307)
// It returns error if ListAndWatch didn't even try to initialize watch.
func (r *Reflector) ListAndWatch(stopCh <-chan struct{}) error {
// 当前为客户端首次请求资源的情况
if err := func() error {
go func() {
defer func() {
if r := recover(); r != nil {
panicCh <- r
}
}()
// 1. 向 apiserver 发送请求
// 如果支持 listerWatcher,则尝试以 chunks 的方式获取资源列表; 否则第一个列表就返回完整的响应
pager := pager.New(pager.SimplePageFunc(func(opts metav1.ListOptions) (runtime.Object, error) {
return r.listerWatcher.List(opts)
}))
if r.WatchListPageSize != 0 {
pager.PageSize = r.WatchListPageSize
}
// Pager falls back to full list if paginated list calls fail due to an "Expired" error.
list, err = pager.List(context.Background(), options)
close(listCh)
}()
// 2. 读取响应 以 channel通道的方式获取上面 goroutine 的响应结果
select {
case <-stopCh:
return nil
case r := <-panicCh:
panic(r)
case <-listCh:
}
if err != nil {
return fmt.Errorf("%s: Failed to list %v: %v", r.name, r.expectedType, err)
}
// 3.1 从响应结果列表里获取版本号信息
listMetaInterface, err := meta.ListAccessor(list)
resourceVersion = listMetaInterface.GetResourceVersion()
items, err := meta.ExtractList(list)
if err != nil {
return fmt.Errorf("%s: Unable to understand list result %#v (%v)", r.name, list, err)
}
// 3.2 根据上次获取的版本号同步最新记录, 更新 Store(Delta FIIO queue) 为最新内容
if err := r.syncWith(items, resourceVersion); err != nil {
return fmt.Errorf("%s: Unable to sync list result: %v", r.name, err)
}
// 3.3 更新最新版本号
r.setLastSyncResourceVersion(resourceVersion)
return nil
}
// 非首次则根据版本号来获取最新变更资源
for {
// give the stopCh a chance to stop the loop, even in case of continue statements further down on errors
select {
case <-stopCh:
return nil
default:
}
timeoutSeconds := int64(minWatchTimeout.Seconds() * (rand.Float64() + 1.0))
options = metav1.ListOptions{
ResourceVersion: resourceVersion,
TimeoutSeconds: &timeoutSeconds,
AllowWatchBookmarks: false,
}
// 根据版本号获取最新资源,并将更新信息写入 Delta Fifo Queue
w, err := r.listerWatcher.Watch(options)
if err := r.watchHandler(w, &resourceVersion, resyncerrc, stopCh); err != nil {
if err != errorStopRequested {
klog.Warningf("%s: watch of %v ended with: %v", r.name, r.expectedType, err)
}
return nil
}
}
}
对于首次访问 apiserver,如果支持 listerWatcher 的话,则以 chunk 的方式获取资源 ,否则一次性获取完整的资源信息,然后再从响应结果里读取当前资源信息号。
当获取资源列表后,对于以后更新的资源,则需要根据 上次的版本号 来监控以后变更的资源,这样就可以只监控后续变更的资源即可,大大减少数据的传输,即这里是以 增量 方式获取资源,后续的操作从这个 增量队列 里获取资源信息即可。
上面这些对应的正是架构图中的 1) List & Watch 步骤。
我们再看一下 r.watchHandler 的实现
// watchHandler watches w and keeps *resourceVersion up to date.
func (r *Reflector) watchHandler(w watch.Interface, resourceVersion *string, errc chan error, stopCh <-chan struct{}) error {
...
loop:
for {
select {
case <-stopCh:
return errorStopRequested
case err := <-errc:
return err
case event, ok := <-w.ResultChan():
if !ok {
break loop
}
if event.Type == watch.Error {
return apierrs.FromObject(event.Object)
}
if e, a := r.expectedType, reflect.TypeOf(event.Object); e != nil && e != a {
utilruntime.HandleError(fmt.Errorf("%s: expected type %v, but watch event object had type %v", r.name, e, a))
continue
}
meta, err := meta.Accessor(event.Object)
if err != nil {
utilruntime.HandleError(fmt.Errorf("%s: unable to understand watch event %#v", r.name, event))
continue
}
newResourceVersion := meta.GetResourceVersion()
// 更新 Delta Fifo Queue
switch event.Type {
case watch.Added:
// 对应 tools/cache/delta_fifo.go#L171-L178
err := r.store.Add(event.Object)
if err != nil {
utilruntime.HandleError(fmt.Errorf("%s: unable to add watch event object (%#v) to store: %v", r.name, event.Object, err))
}
case watch.Modified:
err := r.store.Update(event.Object)
if err != nil {
utilruntime.HandleError(fmt.Errorf("%s: unable to update watch event object (%#v) to store: %v", r.name, event.Object, err))
}
case watch.Deleted:
err := r.store.Delete(event.Object)
if err != nil {
utilruntime.HandleError(fmt.Errorf("%s: unable to delete watch event object (%#v) from store: %v", r.name, event.Object, err))
}
case watch.Bookmark:
// A `Bookmark` means watch has synced here, just update the resourceVersion
default:
utilruntime.HandleError(fmt.Errorf("%s: unable to understand watch event %#v", r.name, event))
}
*resourceVersion = newResourceVersion
r.setLastSyncResourceVersion(newResourceVersion)
eventCount++
}
}
watchDuration := r.clock.Since(start)
if watchDuration < 1*time.Second && eventCount == 0 {
return fmt.Errorf("very short watch: %s: Unexpected watch close - watch lasted less than a second and no items received", r.name)
return nil
}
这里只是对增量队列 Delta Fifo queue 里的资源进行了更新操作,其实现代码见 https://github.com/kubernetes/client-go/blob/v12.0.0/tools/cache/delta_fifo.go#L171-L220 , 其对应的正是 2)Add Object 这一步。
对于 3)Pop Object 这个操作入口函数为 processLoop ( https://github.com/kubernetes/client-go/blob/v12.0.0/tools/cache/controller.go#L139-L161)
// /tools/cache/controller.go
func (c *controller) processLoop() {
for {
// 从 Delta Fifo Queue 读取对象
obj, err := c.config.Queue.Pop(PopProcessFunc(c.config.Process))
if err != nil {
if err == FIFOClosedError {
return
}
if c.config.RetryOnError {
// This is the safe way to re-enqueue.
c.config.Queue.AddIfNotPresent(obj)
}
}
}
}
其增量队列Pop实现见
// /tools/cache/delta_fifo.go
// Pop returns a 'Deltas', which has a complete list of all the things
// that happened to the object (deltas) while it was sitting in the queue.
func (f *DeltaFIFO) Pop(process PopProcessFunc) (interface{}, error) {
f.lock.Lock()
defer f.lock.Unlock()
for {
for len(f.queue) == 0 {
// 阻塞方式获取一个对象
// When the queue is empty, invocation of Pop() is blocked until new item is enqueued.
// When Close() is called, the f.closed is set and the condition is broadcasted.
// Which causes this loop to continue and return from the Pop().
if f.IsClosed() {
return nil, FIFOClosedError
}
f.cond.Wait()
}
// f.queue 是一个slice, 这里获取首个元素后并更新这个切片
id := f.queue[0]
f.queue = f.queue[1:]
if f.initialPopulationCount > 0 {
f.initialPopulationCount--
}
// 将id作为key从items这个 map 中获取 Deltas 信息
item, ok := f.items[id]
if !ok {
// Item may have been deleted subsequently.
continue
}
delete(f.items, id)
// 这里 process 是下一步的进入
err := process(item)
if e, ok := err.(ErrRequeue); ok {
f.addIfNotPresent(id, item)
err = e.Err
}
// Don't need to copyDeltas here, because we're transferring
// ownership to the caller.
return item, err
}
}
这个 process 函数在这里是作为一个参数传递过来的,其声明位置为
// /tools/cache/controller.go
func newInformer(
lw ListerWatcher,
objType runtime.Object,
resyncPeriod time.Duration,
h ResourceEventHandler,
clientState Store,
) Controller {
...
cfg := &Config{
...
Process: func(obj interface{}) error {
// from oldest to newest
for _, d := range obj.(Deltas) {
switch d.Type {
case Sync, Added, Updated:
if old, exists, err := clientState.Get(d.Object); err == nil && exists {
// 对应第 4) 和 5) 步骤
if err := clientState.Update(d.Object); err != nil {
return err
}
h.OnUpdate(old, d.Object)
} else {
if err := clientState.Add(d.Object); err != nil {
return err
}
h.OnAdd(d.Object)
}
case Deleted:
if err := clientState.Delete(d.Object); err != nil {
return err
}
h.OnDelete(d.Object)
}
}
return nil
},
}
return New(cfg)
}
对应的是 Config.Process 这个函数。
对于架构图中的 4)Add Object 和 5)Store Object & Key 对应的则是对 clientState 的调用。
而 6)Dispatch Event Handler functions 则为对 对象 h 的调用,它是一个实现了 Resource Event Handlers 接口的结构体,它有三个实现方法 h.OnAdd 、h.OnUpdate 和 h.OnDelete,而这三个方法原型已在 main 函数里实现。
// /examples/workqueue/main.go
func main() {
...
// Bind the workqueue to a cache with the help of an informer. This way we make sure that
// whenever the cache is updated, the pod key is added to the workqueue.
// Note that when we finally process the item from the workqueue, we might see a newer version
// of the Pod than the version which was responsible for triggering the update.
indexer, informer := cache.NewIndexerInformer(podListWatcher, &v1.Pod{}, 0, cache.ResourceEventHandlerFuncs{
AddFunc: func(obj interface{}) {
key, err := cache.MetaNamespaceKeyFunc(obj)
if err == nil {
queue.Add(key)
}
},
UpdateFunc: func(old interface{}, new interface{}) {
key, err := cache.MetaNamespaceKeyFunc(new)
if err == nil {
queue.Add(key)
}
},
DeleteFunc: func(obj interface{}) {
// IndexerInformer uses a delta queue, therefore for deletes we have to use this
// key function.
key, err := cache.DeletionHandlingMetaNamespaceKeyFunc(obj)
if err == nil {
queue.Add(key)
}
},
}, cache.Indexers{})
...
}
这里使用的结构体名为 cache.ResourceEventHandlerFuncs ()
在 main 函数里的 queue.Add(key) 则对应的是步骤 7) Enqueue Object key, 将 key 写入一个 workqueue 队列。
而对于 8)Get key 则对应的是 controller.processNextItem()
// /examples/workqueue/main.go
func (c *Controller) processNextItem() bool {
// Wait until there is a new item in the working queue
// 对应 8 步骤,从wprkqueue 里读取一个 key
key, quit := c.queue.Get()
if quit {
return false
}
// Tell the queue that we are done with processing this key. This unblocks the key for other workers
// This allows safe parallel processing because two pods with the same key are never processed in
// parallel.
defer c.queue.Done(key)
// Invoke the method containing the business logic
err := c.syncToStdout(key.(string))
// 出错,重试 5 次
// Handle the error if something went wrong during the execution of the business logic
c.handleErr(err, key)
return true
}
从 workqueue 里获取一个key, 通过 controller.syncToStdout() 9) Get Object for key处理。最后调用 c.queue.Done() 表示当前 key 处理完毕。
而 9) Get Object for key 对应 controller.syncToStdout() 函数的实现
// /examples/workqueue/main.go
func (c *Controller) syncToStdout(key string) error {
// 对应步骤 9,从 index 里读取对象
obj, exists, err := c.indexer.GetByKey(key)
if err != nil {
klog.Errorf("Fetching object with key %s from store failed with %v", key, err)
return err
}
if !exists {
// Below we will warm up our cache with a Pod, so that we will see a delete for one pod
fmt.Printf("Pod %s does not exist anymoren", key)
} else {
// Note that you also have to check the uid if you have a local controlled resource, which
// is dependent on the actual instance, to detect that a Pod was recreated with the same name
fmt.Printf("Sync/Add/Update for Pod %sn", obj.(*v1.Pod).GetName())
}
return nil
}
可以看到对 workqueue 的写入与读取全部在 Custom Controller 部分来实现的,有时候对一个对象处理会出现失败的情况,这种情况下就需要对其 key 进行 RateLimited 了。
// handleErr checks if an error happened and makes sure we will retry later.
func (c *Controller) handleErr(err error, key interface{}) {
if err == nil {
// Forget about the #AddRateLimited history of the key on every successful synchronization.
// This ensures that future processing of updates for this key is not delayed because of
// an outdated error history.
c.queue.Forget(key)
return
}
// This controller retries 5 times if something goes wrong. After that, it stops trying.
if c.queue.NumRequeues(key) < 5 {
klog.Infof("Error syncing pod %v: %v", key, err)
// Re-enqueue the key rate limited. Based on the rate limiter on the
// queue and the re-enqueue history, the key will be processed later again.
c.queue.AddRateLimited(key)
return
}
c.queue.Forget(key)
// Report to an external entity that, even after several retries, we could not successfully process this key
runtime.HandleError(err)
klog.Infof("Dropping pod %q out of the queue: %v", key, err)
}
queue.AddRateLimted(key) 表示 过一段时间 将当前 key重新写入 workqueue 里,同时累计当前key的重试次数, 如果重试多次(当前示例为5次)仍失败的话,则调用 runtime.HandleError(err) 处理。
c.queue.Forget 表示一旦key完成,则清除其重试记录,避免影响下次重试,可以看出来 Forget 是对重试行为的处理,这个与 c.queue.Done() 的作用是不一样的。
至此整个架构图中的每个步骤我们基本介绍完了,对于部分细节问题可能还需要花一些时间进行消化。
SharedInformer
如果在一个应用中有多处相互独立的业务逻辑都需要监控同一种资源对象,用户会编写多个 Informer 来进行处理。这会导致应用中发起对 K8s API Server 同一资源的多次 ListAndWatch 调用,并且每一个 Informer 中都有一份单独的本地缓存,增加了内存占用。
K8s 在 client go 中基于 Informer 之上再次做了一层封装,提供了 SharedInformer 机制。采用 SharedInformer 后,客户端对同一种资源对象只会有一个对 API Server 的 ListAndWatch 调用,多个 Informer 也会共用同一份缓存,减少了对 API Server 的请求,提高了性能。
而对 SharedInformer 对象的获取一般是通过 SharedInformerFactory 工厂模式来获取
// SharedInformerFactory provides shared informers for resources in all known
// API group versions.
在内部通过调用 InformerFor() 方法从 cache 中获取某一资源对应的 Informer,如果缓存中不存在,则需要通过指定的函数先创建并加入缓存,然后返回。
// client-go/informers/factory.go#L1870-L208
// InternalInformerFor returns the SharedIndexInformer for obj using an internal client.
func (f *sharedInformerFactory) InformerFor(obj runtime.Object, newFunc internalinterfaces.NewInformerFunc) cache.SharedIndexInformer {
f.lock.Lock()
defer f.lock.Unlock()
informerType := reflect.TypeOf(obj)
informer, exists := f.informers[informerType]
if exists {
return informer
}
resyncPeriod, exists := f.customResync[informerType]
if !exists {
resyncPeriod = f.defaultResync
}
informer = newFunc(f.client, resyncPeriod)
f.informers[informerType] = informer
return informer
}
这里所谓的 cache 其实就是一个 map 对象。
type sharedInformerFactory struct {
informers map[reflect.Type]cache.SharedIndexInformer
}
对于自定义控制器开发,即可以直接选择使用 Controller Runtime (官方Example)库开发,也可以基于 Operator SDK. 开发,还可以基于 kubebuilder 开发框架,其中后两者都会使用 Controller Runtime 库,而 kubebuiler 作为一款开发框架,由于其对开发者极其友好,因此是目前最优先的考虑,参考 Kubebuilder’s Quick Start 了解其用法。
CRD 、CR 和 控制器 的区别
CRD 用于定义自定义资源类型, 如果程序开发中定义的类对象,脱离了控制器没有任何意义;
CR (Custom Resource)是 CRD 定义的资源的实例化对象,是用户自定义的资源类型的具体实例,类似于根据类实例化了一个对象。
自定义控制器 用于管理和控制CRD所定义的自定义资源的行为,类似于 针对实例化对象 的一些基本信息做出相应的动作或行为(实现期望状态与实际状态一致)的控制器。
总结
在Kubernetes开发中,client-go 和 Informers 是两个密切相关的概念。
client-go 是 Kubernetes 官方提供的Go语言客户端库,用于与 Kubernetes API 进行通信。它封装了对 Kubernetes API 的各种操作,包括创建、获取、更新和删除资源等,提供了一组简单易用的API接口,方便开发人员进行与Kubernetes集群的交互。
而 Informers 是 client-go 库中的一部分,它是一种实现了缓存和事件通知机制的机制。Informers 通过监听 Kubernetes API Server上的资源变更事件,将这些事件转换为相应的通知,提供给开发人员使用。这样,开发人员就可以在自己的应用程序中使用Informers来获取最新的资源信息,并进行相应的操作。
使用 Informers 的好处是,避免了频繁地向 Kubernetes API Server 发送请求来获取最新的资源信息,而是通过缓存和事件通知来获取并同步资源的变更。这样可以减轻Kubernetes API Server 的负担,提高应用程序的性能和效率。
因此,可以说 client-go 是Kubernetes开发中与 API Server 进行交互的核心组件,而Informers 是 client-go 的一部分,提供了缓存和事件通知的机制,方便开发人员使用。在使用 client-go 进行Kubernetes开发时,可以选择是否使用 Informers 来获取最新的资源信息。